/case_study_thumb_telit.webp?width=1136&height=639&name=case_study_thumb_telit.webp)









Calling All MSPs – Are you Ready for Channel Daze 2026?

☀️ 10 Days, $15K in Prizes: Channel Daze 2026 is Here! Get ready for the biggest summer giveaway of the year!
Read moreLearn how global companies are transforming their email security to tackle modern threats
Learn how MSPs can revolutionize their email security and profitably grow their businesses
.png?width=50&height=50&name=Untitled%20-%20July%2030%2c%202026%20at%2014.53.38%20(3).png)
Secure email gateways and API-based solutions compared for enterprises and MSPs.
Get an overview of our API, Adaptive AI, and Human Element components
Explore the benefits of a mailbox-level, API-driven email security platform
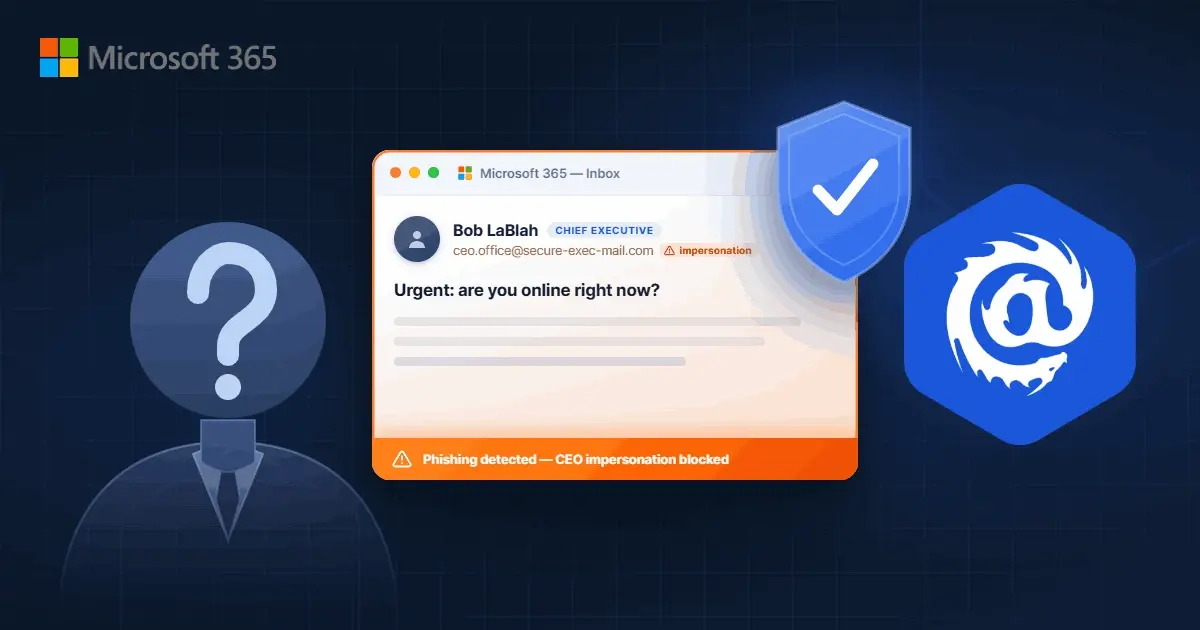
Learn how our Adaptive AI blocks attacks missed by other solutions
See how continuous human insights maximize defense capabilities
Our agents work in concert to anticipate attacks, investigate threats, and educate users
Researches your org like an attacker would, then blocks those threats before they arrive
L2-level forensic investigation across five tracks. Clear verdict in minutes.
Hyper-personalized simulations targeting your highest-risk employees with real OSINT
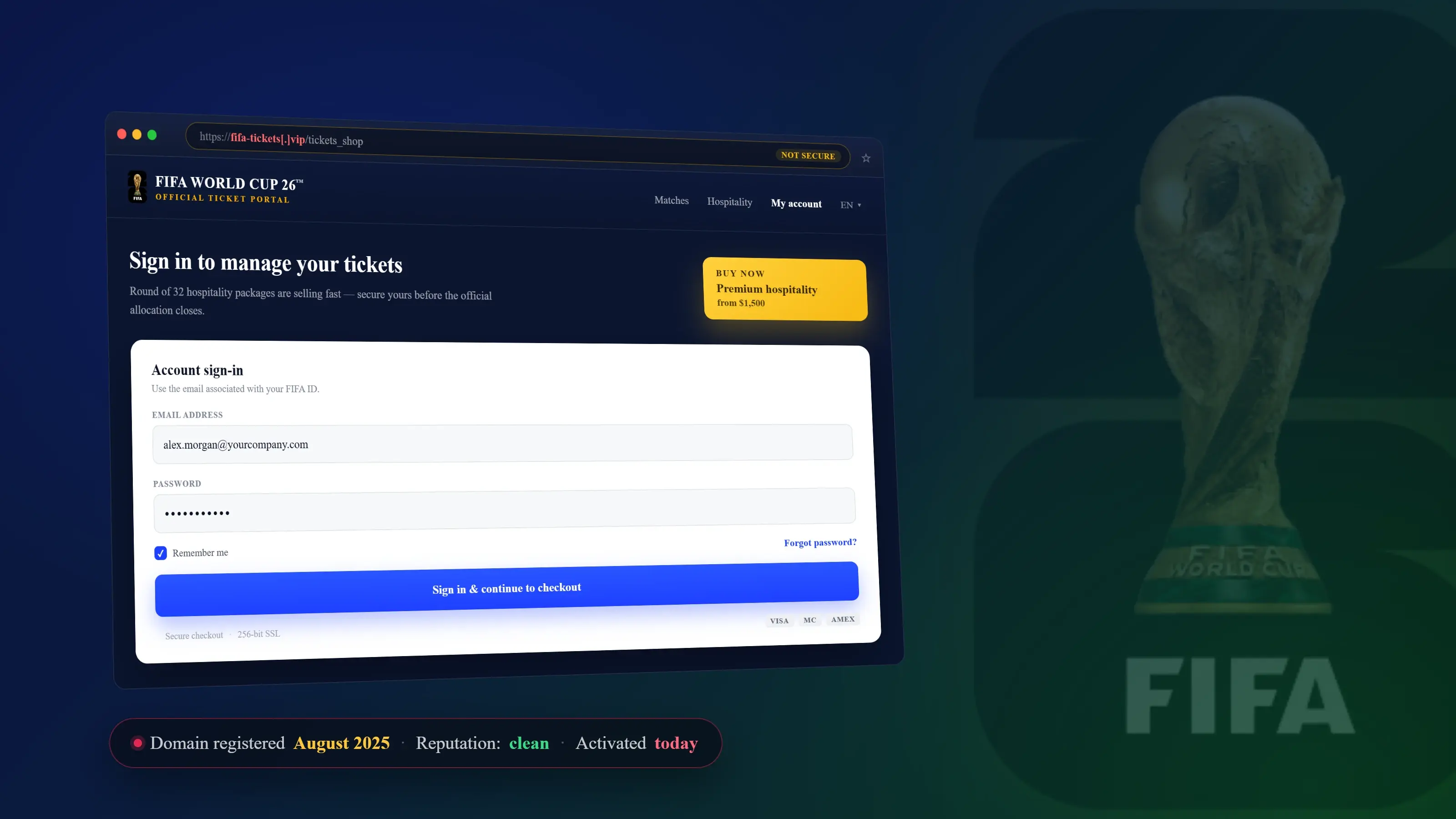
Stop attacks like BEC, VEC, and VIP impersonation
Continuously protect against malicious links and attachments
Prevent, detect, and respond to ATO attacks in real time
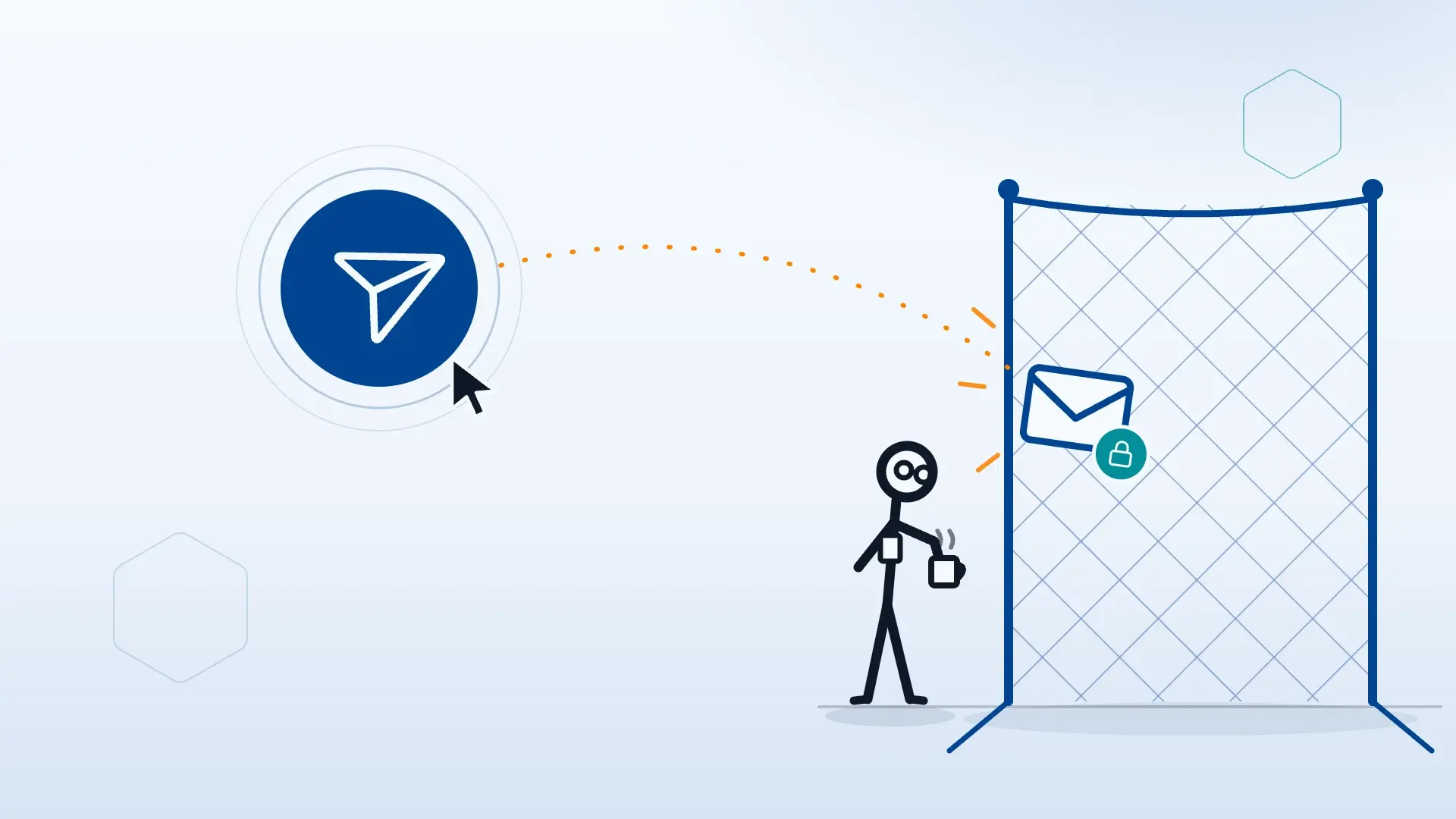
Encrypt outbound email and meet compliance, automatically
Detect and stop deepfake impersonation in MS Teams
Ensure only trusted senders can use your domain
Test your employees with real-world email attack simulations
Build a security-first culture with integrated SAT campaigns


/Leadership%20Headshots/Audian%20Paxson%20Headshot%201000x1000%20032026.webp?width=100&height=100&name=Audian%20Paxson%20Headshot%201000x1000%20032026.webp)